Understanding ROI Align
In the previous post we talked about bilinear interpolation algorithm. In this post we’ll see its application in ROI Align, which is a technique based on bilinear interpolation to smoothly crop a patch from a full-image feature map based on a region proposal, and then resize the cropped patch to a desired spatial size. It was introduced in the Mask R-CNN model, and has been shown to outperform the alternative that does “harsh crop” (i.e. ROI Pooling).
We’ll discuss the main idea of ROI Align and provide numpy implementation. In addition, we’ll discuss how to compute its backward pass when we train a neural network that uses ROI Align.
ROI Align
ROI Align takes as input
- a feature map (e.g. 2-D array)
- a bounding box corresponding to a region proposal. The bounding box is represented by its coordinates
y_min,x_min,y_max,x_max, where0 <= y_min < y_max <= 1and0 <= x_min < x_max <= 1. Note that the coordinates are normalized and denote the relative position w.r.t. the spatial size of the input feature map. - the desired height and width of the output feature map (e.g. height=3, width=3)
Given the 5x5 feature map and the red bounding box shown below, ROI Align outputs a 3x3 feature map computed from the values bounded within the red box.
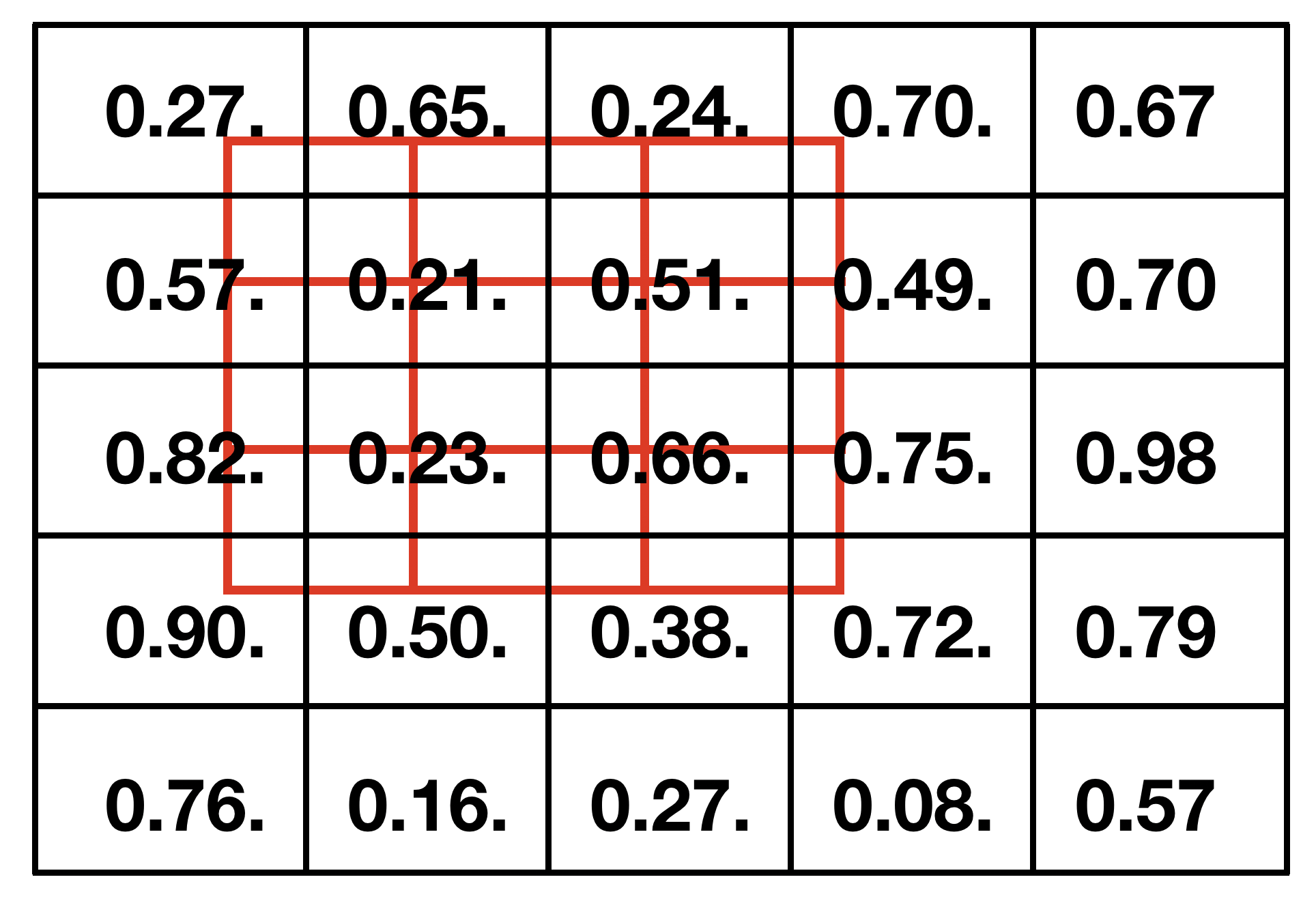
ROI Align crops a patch whose edges may not align with cell boundaries.
You may wonder how we should deal with values that are partially shared by the cells in the red grid, since the black edges are not necessarily aligned with red edges. Actually I was very confused at the beginning when I tried to understand ROI Align, but then I realized that it may be better to think of the cells in the black and red grid as points in 2-D array, as shown below:
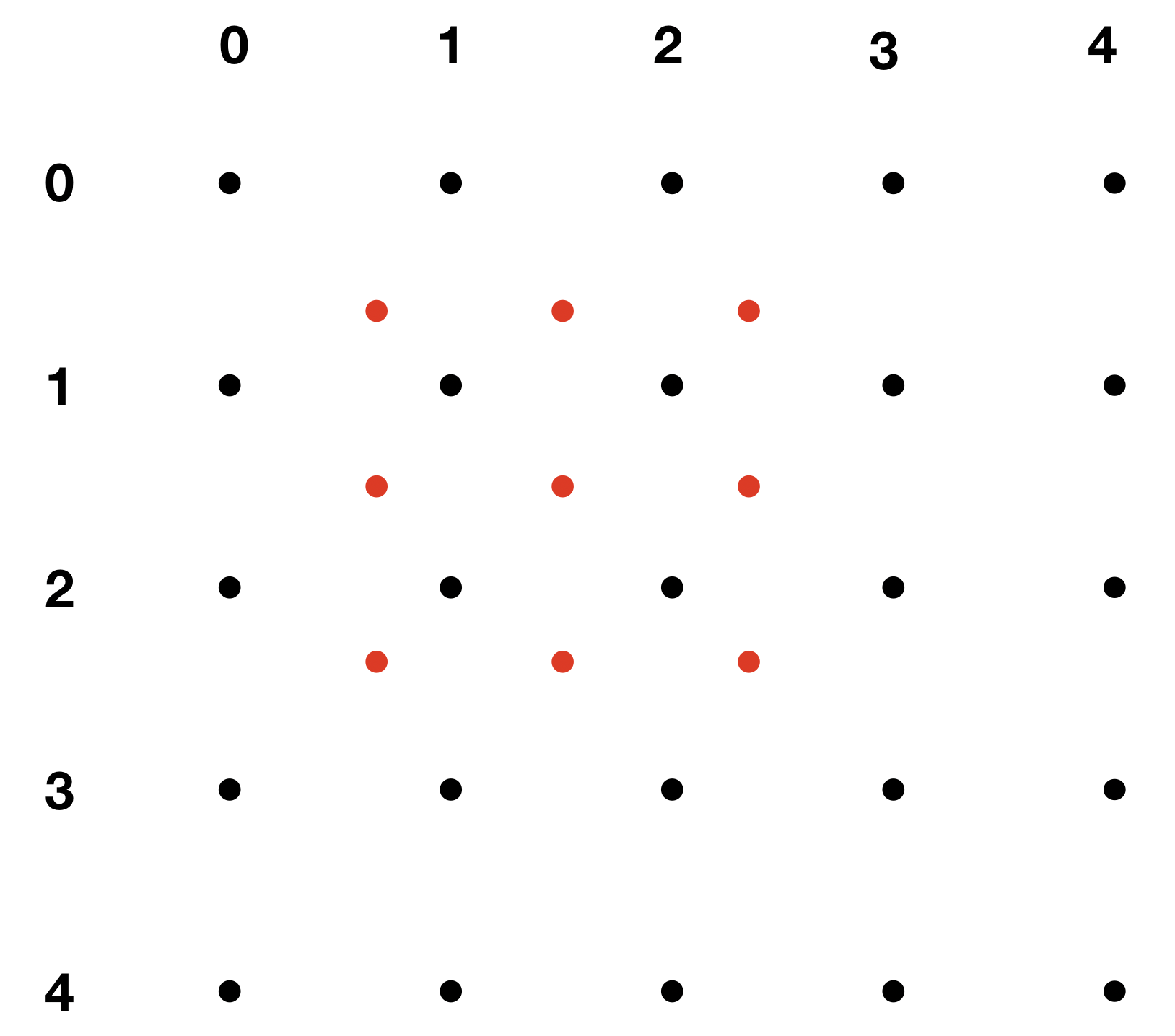
Black dots: cells in input feature map; Red dots: cells in output feature map.
First we need to map the coordinates of red points that vary in to coordinates that vary in . For example, a red point with coordinate is mapped to coordinate . Next, we compute the interpolated values of the red point based on the values of the four black points closest to it, which is exactly the bilinear interpolation problem.
The Algorithm
As we have seen, the cells in the output feature map are represented as evenly-spaced points in 2-D space (red points in the figure above), so first we need to compute their coordinates. And because the coordinates of the bounding box are relative, we also need to convert them to absolute coordinates:
y_coordinates = np.linspace(y_min, y_max, height) * (img_height - 1)
x_coordinates = np.linspace(x_min, x_max, width) * (img_width - 1)
where img_height and img_width are height and width of input feature map, and height and width are the desired height and width of output feature map.
Given the coordinate (may be fractional) [y, x] of a red point, we can find the coordinate of the upper left, upper right, lower left, lower right neighbor: [y_l, x_l], [y_l, x_h], [y_h, x_l], [y_h, x_h]
where
y_l, y_h = np.floor(y).astype('int32'), np.ceil(y).astype('int32')
x_l, x_h = np.floor(x).astype('int32'), np.ceil(x).astype('int32')
Putting together, we have the algorithm for ROI align:
import numpy as np
def roi_align(image, box, height, width):
"""
`image` is a 2-D array, representing the input feature map
`box` is a list of four numbers
`height` and `width` are the desired spatial size of output feature map
"""
y_min, x_min, y_max, x_max = box
img_height, img_width = image.shape
feature_map = []
for y in np.linspace(y_min, y_max, height) * (img_height - 1):
for x in np.linspace(x_min, x_max, width) * (img_width - 1):
y_l, y_h = np.floor(y).astype('int32'), np.ceil(y).astype('int32')
x_l, x_h = np.floor(x).astype('int32'), np.ceil(x).astype('int32')
a = image[y_l, x_l]
b = image[y_l, x_h]
c = image[y_h, x_l]
d = image[y_h, x_h]
y_weight = y - y_l
x_weight = x - x_l
val = a * (1 - x_weight) * (1 - y_weight) + \
b * x_weight * (1 - y_weight) + \
c * y_weight * (1 - x_weight) + \
d * x_weight * y_weight
feature_map.append(val)
return np.array(feature_map).reshape(height, width)
We verify the correctness of our implementation by comparing it with the reference implementation. Actually the function tf.image.crop_and_resize implements ROI align.
Given a 5x6 input feature map
array([[251., 44., 47., 104., 178., 101.],
[ 93., 46., 73., 218., 192., 22.],
[ 98., 85., 122., 144., 172., 151.],
[227., 22., 58., 27., 144., 160.],
[ 64., 77., 192., 18., 253., 31.]], dtype=float32)
and bounding box
array([[0.32, 0.05, 0.43, 0.54]])
we generate the output feature map of shape [3, 2].
Our implementation returns
array([[ 85.03 , 164.112],
[ 88. , 155.95 ],
[ 90.97 , 147.788]])
which is the same as what is returned by tf.image.crop_and_resize.
Vectorized Version
Again, we should make our implementation free of python for loops by taking advantage of numpy’s vectorized operation:
import numpy as np
def roi_align_vectorized(image, box, height, width):
"""
`image` is a 2-D array, representing the input feature map
`box` is a list of four numbers
`height` and `width` are the desired spatial size of output feature map
"""
y_min, x_min, y_max, x_max = box
img_height, img_width = image.shape
y, x = np.meshgrid(
np.linspace(y_min, y_max, height) * (img_height - 1),
np.linspace(x_min, x_max, width) * (img_width - 1))
y = y.transpose().ravel()
x = x.transpose().ravel()
image = image.ravel()
y_l, y_h = np.floor(y).astype('int32'), np.ceil(y).astype('int32')
x_l, x_h = np.floor(x).astype('int32'), np.ceil(x).astype('int32')
a = image[y_l * img_width + x_l]
b = image[y_l * img_width + x_h]
c = image[y_h * img_width + x_l]
d = image[y_h * img_width + x_h]
y_weight = y - y_l
x_weight = x - x_l
feature_map = a * (1 - x_weight) * (1 - y_weight) + \
b * x_weight * (1 - y_weight) + \
c * y_weight * (1 - x_weight) + \
d * x_weight * y_weight
return feature_map.reshape(height, width)
Backward Pass of ROI Align
As in the backward pass of Bilinear Resizing, we need to properly route the gradient w.r.t. a, b, c, and d to a subset of entries in the input image. And again, the backward pass of ROI Align does not need to use the value of the forward pass.
def roi_align_vectorized_backward(image, box, height, width, grad):
"""
`image` is a 2-D array, representing the input feature map
`box` is a list of four numbers
`height` and `width` are the desired spatial size of output feature map
`grad` is a 2-D array of shape [height, width], holding gradient backpropped
from downstream layer.
"""
y_min, x_min, y_max, x_max = box
img_height, img_width = image.shape
y, x = np.meshgrid(
np.linspace(y_min, y_max, height) * (img_height - 1),
np.linspace(x_min, x_max, width) * (img_width - 1))
y = y.transpose().ravel()
x = x.transpose().ravel()
image = image.ravel()
y_l, y_h = np.floor(y).astype('int32'), np.ceil(y).astype('int32')
x_l, x_h = np.floor(x).astype('int32'), np.ceil(x).astype('int32')
y_weight = y - y_l
x_weight = x - x_l
grad = grad.ravel()
# gradient wrt `a`, `b`, `c`, `d`
d_a = (1 - x_weight) * (1 - y_weight) * grad
d_b = x_weight * (1 - y_weight) * grad
d_c = y_weight * (1 - x_weight) * grad
d_d = x_weight * y_weight * grad
# [4 * height * width]
grad = np.concatenate([d_a, d_b, d_c, d_d])
# [4 * height * width]
indices = np.concatenate([y_l * img_width + x_l,
y_l * img_width + x_h,
y_h * img_width + x_l,
y_h * img_width + x_h])
# we must route gradients in `grad` to the correct indices of `image` in
# `indices`
# use numpy's broadcasting rule to generate 2-D array of shape
# [4 * height * width, img_height * img_width]
indices = (indices.reshape((-1, 1)) ==
np.arange(img_height * img_width).reshape((1, -1)))
d_image = np.apply_along_axis(lambda col: grad[col].sum(), 0, indices)
return d_image.reshape(img_height, img_width)
We use some test case to verify the correctness of the backward pass:
import tensorflow as tf
import numpy as np
tf.enable_eager_execution()
with tf.GradientTape() as g:
image = tf.convert_to_tensor(
np.random.randint(0, 255, size=(1, 3, 8, 1)).astype('float32'))
boxes = np.array([[0.32, 0.05, 0.43, 0.54]])
g.watch(image)
output = tf.image.crop_and_resize(image, boxes, [0], [6, 6])
grad_val = np.random.randint(-10, 10, size=(6, 6)).astype('float32')
grad_tf = g.gradient(output, image, grad_val.reshape(1, 6, 6, 1))
grad = roi_align_vectorized_backward(
image[0, :, :, 0].numpy(), boxes[0], 6, 6, grad_val)
# compare if `grad_tf` and `grad` are equal.