Understanding Bilinear Image Resizing
Resizing an image (or a feature map) to a desired spatial dimension is a common operation when building computer vision applications based on convolutional neural networks. For example, some semantic segmentation models (like FCN or DeepLab) generate a feature map with a large stride S (i.e. height and width of the feature map is 1/S of that of the image, where S = 16 or 32), which must be resized back to the exact spatial dimension of the original image to provide pixelwise prediction.
Bilinear interpolation is an intuitive algorithm for image resizing. It is a generalization of linear interpolation which only works on 1-D array. In this post, we will discuss the intuition behind interplation algorithms (linear or bilinear), and provide numpy implementations so you will understand exactly how they work. We will also investigate how to compute the backward pass of bilinear resizing when we train a neural network which uses this operation.
Linear Interpolation
We will first discuss Linear Interpolation which is more common and easier to understand.
Let’s say we have two points on a straight line with coordinate and , and they are associated with values and . Now if we have a third point with coordinate where , how do we interpolate the values of cooridnates and at coordinate ?
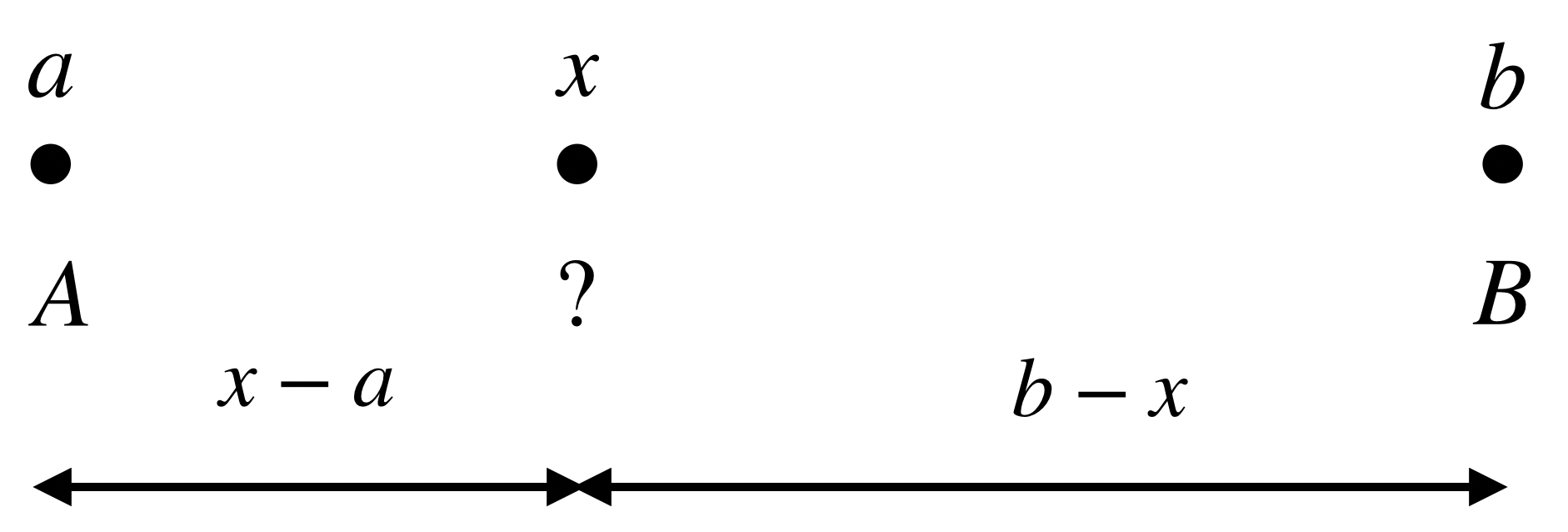
Linear Interpolation between two ponits.
The Linear Interpolation computes it as a weighted average of the values associated with the two points, where the weights are proportional to the distance between and , and and .
or
where .
The weight for is proportional to ’s distance to (rather than ), while the weight for is proportional to its distnace to (rather than ). When moves to , its value becomes ; similarly, becomes when moves to .
Linearly Resize 1-D Array
Given that we know how to do interpolation between two points, let’s consider a more general scenario: we have a 1-D array a of size n (e.g n = 5 ), and we wish to stretch or shrink the array to a differet size m (e.g m = 4), where the values in the new array b is somehow computed from the original array in a linear fashion.
Image we place the n = 5 points on a straight line, where they are spaced by a distance of 1.0. Now image there is another straight line that runs parallel to it, where we place the points of the new array. Note that we make the coordinates of the first and last element of the new array the same as their counterparts in the orignal array (i.e. 0.0 and 4.0).
How do we get the values of array b? Well, it makes sense to let b[0] == a[0] and b[3] == a[4], because they have the same coordinates. For those points in the new array for which we don’t have corresponding points in the original array (i.e. b[1] and b[2]), we can map them to the original array where they will have fractionally-valued coordinates (4/3 and 8/3). Then b[4/3] and b[8/3] can be computed using the Linear Interpolation approach from a[1], a[2] and a[2], a[3].
Now the question reduces to how do we map the coordinates from the new array b to the original array a. We notice that the mapping depends on the ratio of the length of “integer intervals” — in this case, it’s 4/3 (i.e. (n - 1)/(m - 1)). For element in array b with index i, its mapped coordinate in array a is ratio * i, and we compute the interpolation using the values of the two neighboring elements a[floor(ratio * i)] and a[ceil(ratio * i)].
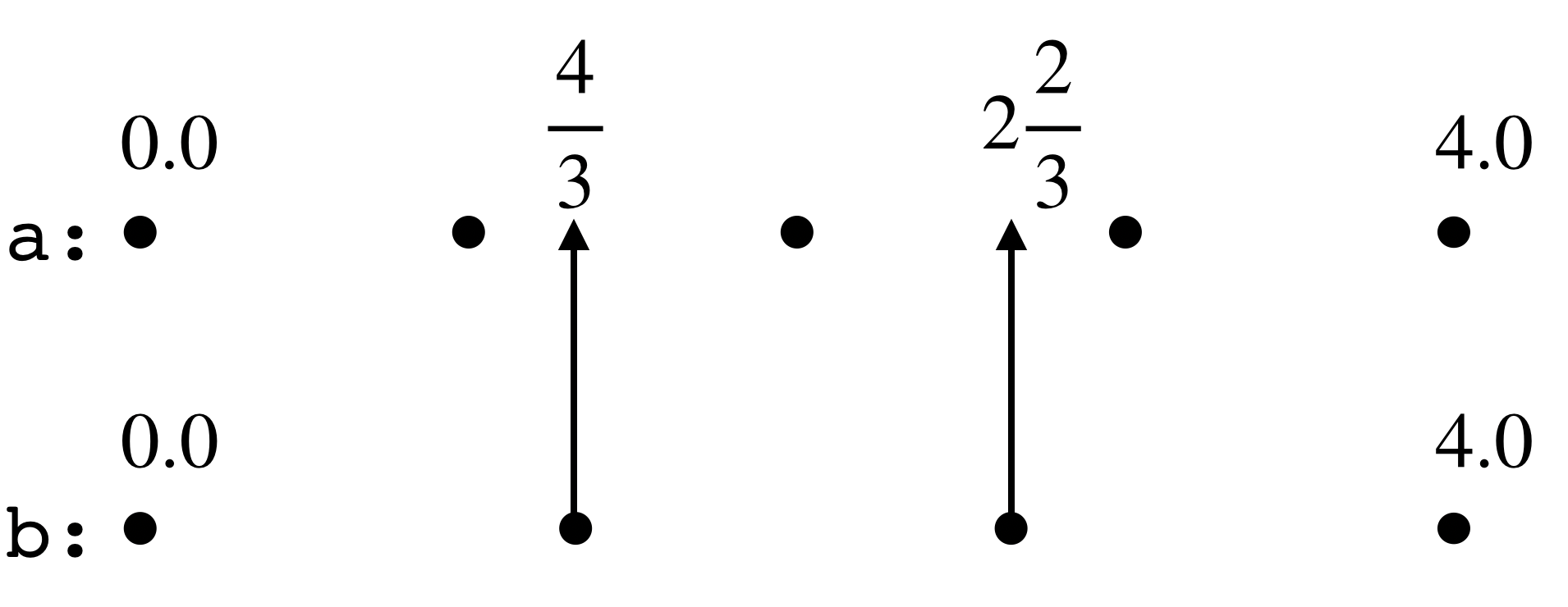
Resize 1-D array.
Putting together, we have the algorithm for linearly resizing 1-D array:
import math
def linear_resize(in_array, size):
"""
`in_array` is the input array.
`size` is the desired size.
"""
ratio = (len(in_array) - 1) / (size - 1)
out_array = []
for i in range(size):
low = math.floor(ratio * i)
high = math.ceil(ratio * i)
weight = ratio * i - low
a = in_array[low]
b = in_array[high]
out_array.append(a * (1 - weight) + b * weight)
return out_array
Bilinear Interpolation
Like linearly resizing a 1-D array, bilinearly resizing a 2-D array relies on bilinear interpolation, which can be broken down into linear resizing operations in (height) and (width) dimension. Suppose we have four points with coordinates , , , and and associated valued , , , and .
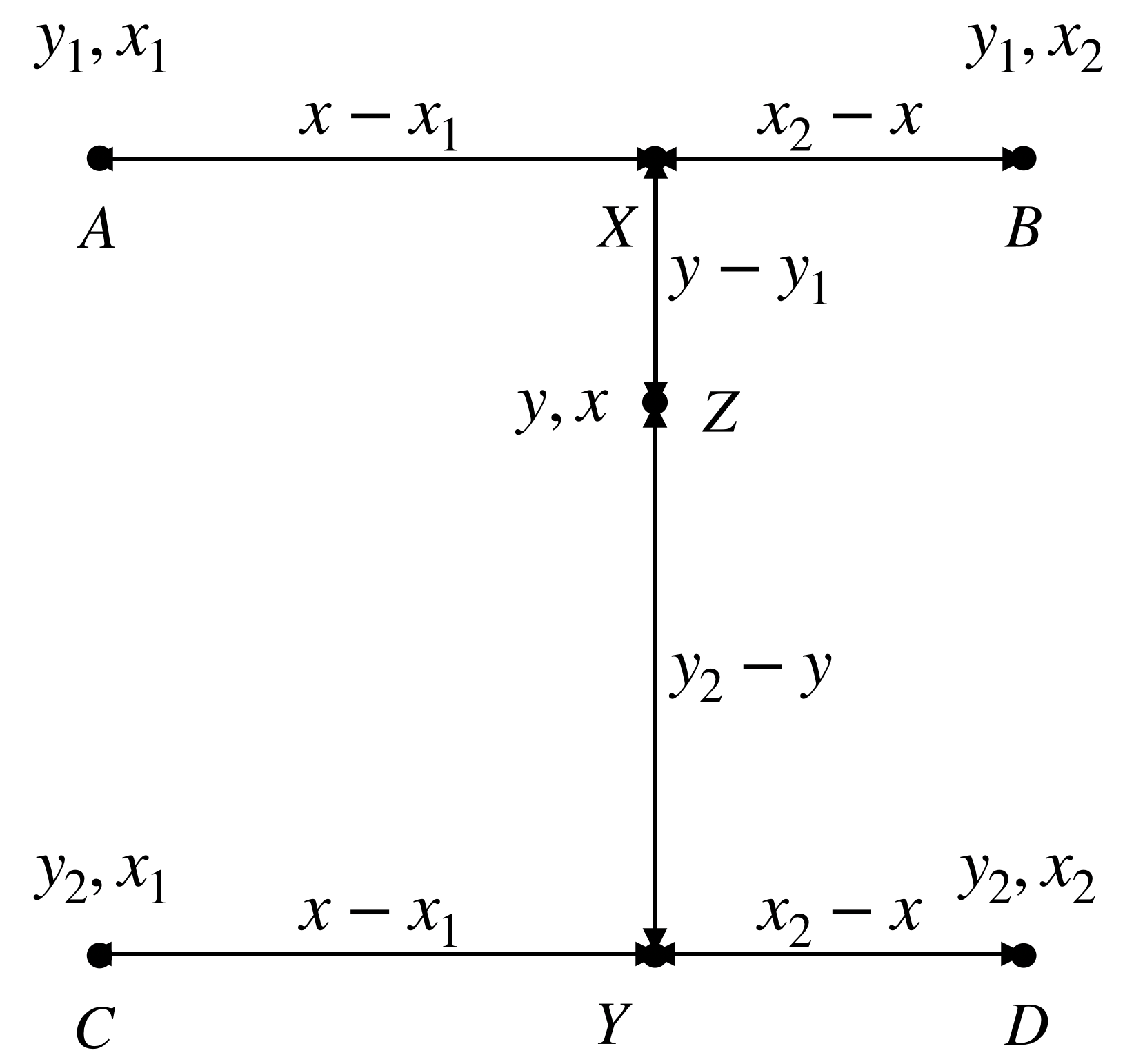
Bilinear interpolation between four points.
We first compute the interpolated value of and in the width dimension,
Then we will do linear interpolation between the two interpolated values and in the height dimension,
where and .
Bilinearly Resize 2-D Array
Bilinearly resizing a 2-D array is very much like linearly resizing a 1-D array. We first need to find the ratios (now in two dimensions),
ratio_y = (img_height - 1) / (height - 1)
ratio_x = (img_width - 1) / (width - 1)
where height and width are the dimensions of the new 2-D array.
Suppose we wish to compute the interpolated value for the point at coordinate [i, j] where 0 <= i < height and 0 <= j < width. Its mapped coordinate in the original 2-D array is computed as [y_ratio * i, x_ratio * j]. Then the coordinates of the four points that are closest to [i, j] are [y_l, x_l], [y_l, x_h], [y_h, x_l], [y_h, x_h], where
x_l, y_l = math.floor(x_ratio * j), math.floor(y_ratio * i)
x_h, y_h = math.ceil(x_ratio * j), math.ceil(y_ratio * i)
Putting together, we have the algorithm for bilinearly resizing 2-D array:
import math
def bilinear_resize(image, height, width):
"""
`image` is a 2-D numpy array
`height` and `width` are the desired spatial dimension of the new 2-D array.
"""
img_height, img_width = image.shape[:2]
resized = np.empty([height, width])
x_ratio = float(img_width - 1) / (width - 1) if width > 1 else 0
y_ratio = float(img_height - 1) / (height - 1) if height > 1 else 0
for i in range(height):
for j in range(width):
x_l, y_l = math.floor(x_ratio * j), math.floor(y_ratio * i)
x_h, y_h = math.ceil(x_ratio * j), math.ceil(y_ratio * i)
x_weight = (x_ratio * j) - x_l
y_weight = (y_ratio * i) - y_l
a = image[y_l, x_l]
b = image[y_l, x_h]
c = image[y_h, x_l]
d = image[y_h, x_h]
pixel = a * (1 - x_weight) * (1 - y_weight) \
+ b * x_weight * (1 - y_weight) + \
c * y_weight * (1 - x_weight) + \
d * x_weight * y_weight
resized[i][j] = pixel
return resized
We verify the correctness of our implementation by comparing it with the reference implementation in tensorflow.
First we need to create a 2-D array populated with random values:
array([[114., 195., 254., 217., 33., 160.],
[110., 91., 184., 143., 190., 124.],
[212., 163., 245., 39., 83., 188.],
[ 23., 206., 62., 7., 5., 206.],
[152., 177., 118., 155., 245., 41.]], dtype=float32)
and we will resize it into a 2-D array with 2 rows and 10 columns.
Our implementation returns
array([[114. , 159. , 201.55556 , 234.33333 , 245.77777 ,
225.22223 , 155.66667 , 53.444443, 89.44444 , 160. ],
[152. , 165.88889 , 170.44444 , 137.66667 , 126.22222 ,
146.77777 , 185. , 235. , 154.33333 , 41. ]],
dtype=float32)
which is the same as the output of tf.image.resize_images(tf.expand_dims(image, axis=2), [2, 10], align_corners=True) (up to the numerical precision).
Finally, let’s test out our implementation to resize a real image


Left: Original image of size 425 by 775. Right: Resized image of size 500 by 500.
Vectorized Version
NOTE: The function bilinear_resize uses python for loop, which runs very slow. We can take advantage of numpy’s vectorized computation on arrays to speed it up.
import numpy as np
def bilinear_resize_vectorized(image, height, width):
"""
`image` is a 2-D numpy array
`height` and `width` are the desired spatial dimension of the new 2-D array.
"""
img_height, img_width = image.shape
image = image.ravel()
x_ratio = float(img_width - 1) / (width - 1) if width > 1 else 0
y_ratio = float(img_height - 1) / (height - 1) if height > 1 else 0
y, x = np.divmod(np.arange(height * width), width)
x_l = np.floor(x_ratio * x).astype('int32')
y_l = np.floor(y_ratio * y).astype('int32')
x_h = np.ceil(x_ratio * x).astype('int32')
y_h = np.ceil(y_ratio * y).astype('int32')
x_weight = (x_ratio * x) - x_l
y_weight = (y_ratio * y) - y_l
a = image[y_l * img_width + x_l]
b = image[y_l * img_width + x_h]
c = image[y_h * img_width + x_l]
d = image[y_h * img_width + x_h]
resized = a * (1 - x_weight) * (1 - y_weight) + \
b * x_weight * (1 - y_weight) + \
c * y_weight * (1 - x_weight) + \
d * x_weight * y_weight
return resized.reshape(height, width)
Backward Pass of Bilinear Resizing
Remember that bilinear resizing is essentially a function where the input is a 2-D array of shape [img_height, img_width] and output is a 2-D array of shape [height, width]. When doing backpropagation, we take as input the gradient grad backpropped from the downstream layer — a 2-D array of the same shape as the output (i.e. [heigth, width]), and we compute the gradient of shape [img_height, img_width] to be backpropped to its upstream layer.
Note that in the forward pass (bilinear_resize_vectorized) we computed the output — resized image — as a linear combination of a, b, c, and d, each of which corresponds to a subset of entries of the input image. The gradient w.r.t to a, b, c, d are simply their coeffients, (1 - x_weight) * (1 - y_weight), x_weight * (1 - y_weight), y_weight * (1 - x_weight), and x_weight * y_weight, multiplied by grad, and they must be properly routed to the corresponding entries in the input image. Detailed implementation are as below:
def bilinear_resize_vectorized_backward(image, height, width, grad):
"""
`image` is a 2-D array, holding the input image
`height` and `width` are the desired spatial dimension of the new 2-D array.
`grad` is a 2-D array of shape [height, width], holding the gradient to be
backpropped to `image`.
"""
img_height, img_width = image.shape
image = image.ravel()
x_ratio = float(img_width - 1) / (width - 1) if width > 1 else 0
y_ratio = float(img_height - 1) / (height - 1) if height > 1 else 0
y, x = np.divmod(np.arange(height * width), width)
x_l = np.floor(x_ratio * x).astype('int32')
y_l = np.floor(y_ratio * y).astype('int32')
x_h = np.ceil(x_ratio * x).astype('int32')
y_h = np.ceil(y_ratio * y).astype('int32')
x_weight = (x_ratio * x) - x_l
y_weight = (y_ratio * y) - y_l
grad = grad.ravel()
# gradient wrt `a`, `b`, `c`, `d`
d_a = (1 - x_weight) * (1 - y_weight) * grad
d_b = x_weight * (1 - y_weight) * grad
d_c = y_weight * (1 - x_weight) * grad
d_d = x_weight * y_weight * grad
# [4 * height * width]
grad = np.concatenate([d_a, d_b, d_c, d_d])
# [4 * height * width]
indices = np.concatenate([y_l * img_width + x_l,
y_l * img_width + x_h,
y_h * img_width + x_l,
y_h * img_width + x_h])
# we must route gradients in `grad` to the correct indices of `image` in
# `indices`, e.g. only entries of indices `y_l * img_width + x_l` in `image`
# gets the gradient backpropped from `a`.
# use numpy's broadcasting rule to generate 2-D array of shape
# [4 * height * width, img_height * img_width]
indices = (indices.reshape((-1, 1)) ==
np.arange(img_height * img_width).reshape((1, -1)))
d_image = np.apply_along_axis(lambda col: grad[col].sum(), 0, indices)
return d_image.reshape((img_height, img_width))
As we can see, when computing the backward pass of bilinear resizing we do not need to store the value of the forward pass.
Finally, we verify the correctness of the backward pass using some test case:
import tensorflow as tf
import numpy as np
tf.enable_eager_execution()
with tf.GradientTape() as g:
image = tf.convert_to_tensor(
np.random.randint(0, 255, size=(1, 3, 8, 1)).astype('float32'))
g.watch(image)
output = tf.image.resize_images(image, [6, 6], align_corners=True)
grad_val = np.random.randint(-10, 10, size=(6, 6)).astype('float32')
grad_tf = g.gradient(
output, image, output_gradients=[grad_val.reshape(1, 6, 6, 1)])
grad = bilinear_resize_vectorized_backward(
image[0, :, :, 0].numpy(), 6, 6, grad_val)
# compare if `grad_tf` and `grad` are equal.