From Likelihood Maximization to Loss Minimization
Loss function is an important component for almost all Machine Learning models, especially neural networks. It compares the prediction that comes out of the model with the groundtruth, and determines how dissimilar they are (i.e. how bad the prediction is). For example, a ConvNet-based object detector performs both the classification task and the regression task — it predicts a vector holding the confidence scores corresponding to different object classes, and another vector describing how the anchor boxes should be shifted and scaled so it can tightly bound the object instances. To measure the quality of the predictions, we compute the cross-entropy loss (Sigmoid or Softmax) for classification task, and Huber loss (a variant of squared error loss) for regression task, between the predictions and their respective groundtruths, and we tune the neural network weights to minimize the losses.
You may wonder why cross-entropy loss and squared-error loss are chosen for classification and regression tasks. In this post I’ll try to justify the choices by providing a probabilistic interpretation of different loss functions. To simplify the disscussion, I’ll use the simplest form of each task — logistic regression and linear regression, as our running examples.
Problem Setup
Logistic regression and linear regression are two closely related and well-established techniques in Statistics. They both take as input observations, each represented as a -dimensional row vector, describing different attributes of a given observation (e.g. height and weight of a person). Also, each observation comes with a label, which is discrete-valued (e.g. 1 or 0) for logistic regression, or continuously valued (e.g. 1.8) for linear regression. Formally, the observations are represented as a matrix , and the labels are represented as a column vector , that is
where is the number of observations and is the number of attributes (or features). Note: to accommodate the additional constant and to simplify notation (See below), we prefixed the matrix with a column of ones.
To generate the predictions, we apply a linear transformation on each observation (i.e. , row of ) — a linear combination of attributes plus a constant. Formally, the predicted values are
where
For linear regression, we’ll output the prediction unchanged. However, for logistic regression, we’ll output an indicator vector, which takes the value of 1 if , and 0 otherwise.
Model label and observations as random variables
The attributes of the observations as well as the labels are referred to as training data, and they are fixed once the process of collecting the training data is finished. However, this process itself may involve certain degree of stochasticity — we may end up collecting a different set of values for if we were to repeat the collecting process; and even if we happen to get the same set of values for as previously collected, the values for the labels may still be different. As a result, we usually model the labels and observations as random variables, so and are just concrete values that the random variables can take on.
Formally, given that the training set contains observations with attributes, we use the random variable () to denote the label for the th observation, and random variables to denote its attributes. So takes on the value of each component of , and take on each row of .
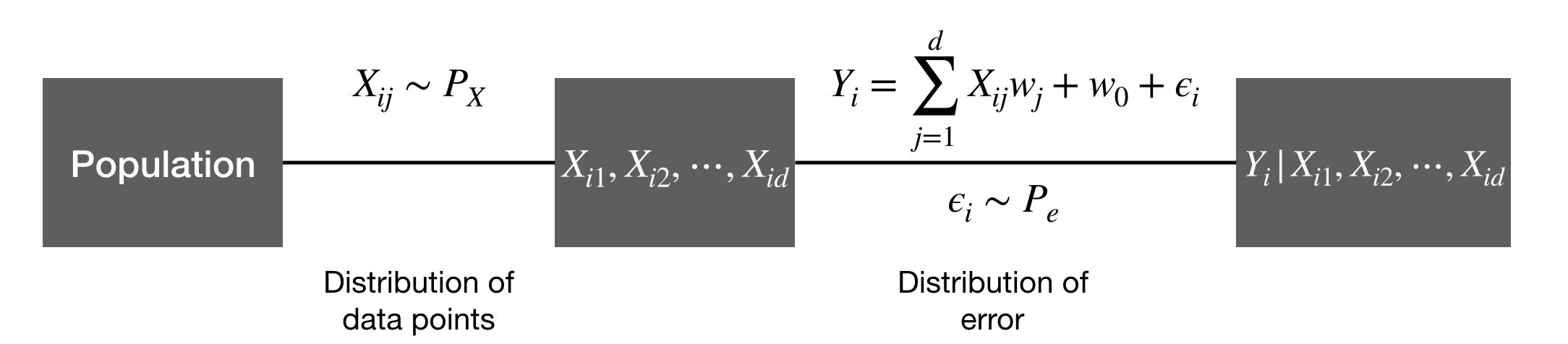
Sample a set of data points with observations, and then sample the corresponding labels.
Note that the stochasticity associated with the random variables is determined by the distribution of samples in a population — we first sample (randomly) a set of data points according to the distribution, then record their attributes; However, the stochasticity associated with is determined by both the distribution of samples (to determine we first need to sample a data point ), and the inevitable error assosicated the labelling the data point (e.g. the measured height may always be slightly different from the true height of an individual). For our discussion, we’ll treat the as fixed, and only discuss — the probability of conditioned on , whose randomness is attributed to the labelling error.
The error distribution
To account for the labelling error, we’ll add an error term to the linear transformation of , and denote the result as
As discussed previously, for linear regression the label (or the predicted label) is just the linear combination (plus the error), so
,while for logistic regression, we add a binarization step:
As for the error term’s distribution, we assume it follows a zero-mean normal distribution,
for linear regression, and a logistic distribution with location being 0 and scale being 1 for logistic regression.
We assume that each data point is labelled independently, so and hence should be i.i.d. (independently and identically distributed).
Maximizing the Likelihood
Now we are ready to derive the probability of conditioned on analytically, i.e, . We’ll find the that maximizes the logarithm of probability, which is equivalent to maximizing the probability itself.
Linear regression
Given equations (1), (2), and , it follows that is a continuous random variable, and . Maximizing the log-likelihood, we have
We have just proved that maximizing the likelihood is equivalent to minimizing the squared error.
Logistic regression
Given equations (1) and (3), it follows that is a discrete random variable that takes on the value of 0 or 1, and iff . We have
where denotes .
The last two steps follows from the fact that , and its cumulative distribution function is just the logistic function, i.e. , and
It follows that .
Maximizing the log-likelihood, we have
Again, we have proved that maximizing the likelihood is equivalent to minimizing the cross-entropy, which is defined between the target distribution (Bernoulli) and predicted distribution .
Miminize the loss
At this point, it’ll be trivial to derive the update algorithm to optimize the losses.
Linear regression
Let the loss function . Using chain rule, we have
Logistic regression
Let and the loss function . Using chain rule, we have
It’s a little surprising that we end up with almost identical update algorithm for both logistic regression and linear regression. In both algorithms, the magnitude of the update depends on the error or , which means if we made a big error in the prediction, we should accordingly make a large stride to update the corredponding weight.
Summary
In this post, we provided a probabilistic interpretation for the principle of loss minimization for linear regression and logistic regression. We discussed the sources of randomness for both labels and inputs, and modeled the labels as random variables conditioned on the observed inputs. We gave assumptions on the probability distributions of the errors, and finally showed that maximizing the likelihood of the labels is equivalent to minimizing the squared error loss or cross entropy loss.